Services
Why DeltaXignia
Why DeltaXignia
Why DeltaXignia
By Business Case
Version Control & Collaboration
Data Consistency & Management
AI & Automation
By Industry
Aviation
Manufacturing
Legal
Why DeltaXignia
Why DeltaXignia
By Business Case
Version Control & Collaboration
Data Consistency & Management
AI & Automation
By Industry
Aviation
Manufacturing
Legal

There has been a slew of recent technology and infrastructure provider outages in the recent past; the ripple effects were immediate and global. Over the past 18 months, outages at Cloudflare, Microsoft Azure, and AWS have demonstrated the real-world impact of DNS and configuration errors. From Cloudflare’s global DNS failures in July to Azure and AWS misconfigurations in October, these incidents highlight how a single change can ripple across services and impact thousands of organisations worldwide. Businesses large and small saw applications falter, customer experiences degrade, and operational visibility blur. For those of us who live and breathe infrastructure, it was yet another reminder that our digital resilience is only as strong as the foundations we often overlook.
At DeltaXignia, we see moments like this not as failures of technology but as opportunities to re-examine how we manage data and configuration complexity at scale. DNS for example, is one of the most fundamental (and fragile) components of modern connectivity. It’s the address book of the internet, invisible when it works perfectly, and painfully visible when it doesn’t.
During the recent outages, our teams and systems were fortunate to remain unaffected. That wasn’t luck; it was design. We rely on Business Continuity planning, which includes using DeltaXignia’s own technology to continuously monitor and validate every DNS configuration change across our systems. This capability doesn’t just alert us when something breaks - it prevents misconfigurations before they occur; we check before we make and change, and after the change is made. This isolates risk domains when external dependencies fail, and ensures our services continue operating autonomously even when the global network stumbles.
Achieving this level of reliability relies on two complementary approaches: proactive measures that prevent issues before they occur, and reactive measures that allow rapid response when unexpected events arise. Let’s take a closer look at how each approach works in practice:
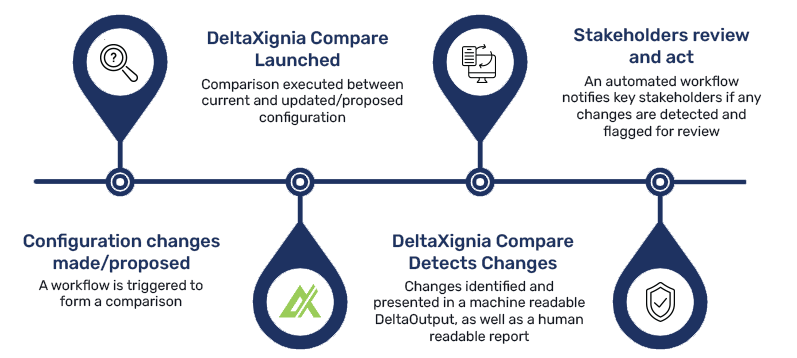
1) A change is made to configuration (DNS for example).
2) An event log is created, which in turn triggers a Lambda function to form a Comparison.
3) DeltaXignia Compare is launched, and a comparison is executed between current configuration ( known, good configuration which is stored securely and is immutable), and the updated configuration received (as part of the trigger in Step 2).
4) DeltaXignia Compare runs against both configuration files, which executes character-by-character change detection, and produces both a machine readable DeltaOutput, and a human readable report; which is stored.
5) Using the machine readable DeltaOutput:
Changes are proposed to a configuration (DNS for example) and a workflow is triggered to:
1) Retrieve the current configuration (again stored securely, and immutable).
2) Execute DeltaXignia Compare against both files (current, and proposed).
3) Machine readable DeltaOuput is generated (along with a human readable report), and workflow decisions follow as a result of:
4) Approval flow is completed.
5) Changes are submitted to our DNS Management Platform using the appropriate format when approved.
For business leaders, this incident highlights a larger truth: resilience is not redundancy. Many organizations invest heavily in multi-region or multi-cloud architectures, believing that more infrastructure equals more resilience. But resilience is not built on capacity - it’s built on visibility, control, and intelligent automation. Without real-time insight into the dependencies that tie your systems together, even the most robust architectures can unravel.
What we’ve learned at DeltaXignia is that the future of operational continuity depends on anticipation, not reaction. We can’t prevent every outage in the global internet fabric - but we can ensure our organizations respond intelligently, automatically, and transparently when they occur. For technology and infrastructure leaders the takeaway is clear: resilience must be treated as a strategic capability, not a technical feature. It’s what protects your brand, your customers, and your credibility when the unpredictable happens.
In the end, outage don’t just test our systems - they test our philosophies. And at DeltaXignia, our philosophy is simple: every change matters - resilience by design, not by reaction.
Get in touch and we’ll help you establish robust, traceable comparison workflows that prevent misconfigurations, strengthen resilience, and keep your systems steady when the wider network stumbles.




From ISO Quality Services Ltd.
